Profiling Caddy
程序剖面(program profile)是在运行时对程序资源使用情况的快照。剖面对于识别问题区域、排查错误和崩溃以及优化代码非常有帮助。
Caddy 使用 Go 的剖面工具 pprof 来捕获剖面,它内置在 go 命令中。
剖面报告 CPU 和内存的使用情况,显示 goroutine 的堆栈跟踪,并有助于查找死锁或高争用的同步原语。
在报告某些 Caddy 的错误时,我们可能会要求提供剖面。本篇文章可以提供帮助。它既描述了如何从 Caddy 获取剖面,也介绍了如何使用和解释得到的 pprof 剖面文件的一般方法。
在开始之前要知道两点:
- Caddy 的剖面不是敏感的安全信息。它们包含的是良性技术读数,而不是内存内容。它们不会授予对系统的访问权限,安全上可以放心共享。
- 剖面开销小,可以在生产环境中收集。实际上,这对许多用户来说是推荐的最佳实践;本文稍后会提到。
获取剖面
剖面可通过 admin 界面 的 /debug/pprof/ 端点获得。在运行 Caddy 的机器上,用浏览器打开:
http://localhost:2019/debug/pprof/
你会看到一个简单的计数表和链接,例如:
| 计数 | 剖面 |
|---|---|
| 79 | allocs |
| 0 | block |
| 0 | cmdline |
| 22 | goroutine |
| 79 | heap |
| 0 | mutex |
| 0 | profile |
| 29 | threadcreate |
| 0 | trace |
| full goroutine stack dump |
这些计数是快速识别泄漏的便捷方法。如果你怀疑有泄漏,反复刷新页面,你会看到其中一个或多个计数持续增加。如果 heap(堆)计数增长,可能是内存泄漏;如果 goroutine 计数增长,可能是 goroutine 泄漏。
点击这些剖面查看它们的样子。有些剖面可能为空,这是很常见的。最常用的剖面是 goroutine(函数栈)、heap(内存)和 profile(CPU)。其他剖面对于排查互斥锁争用或死锁也很有用。
在页面底部,有对每个剖面的简单说明:
- allocs: 对过去所有内存分配的采样
- block: 导致在同步原语上阻塞的堆栈跟踪
- cmdline: 当前程序的命令行调用
- goroutine: 所有当前 goroutine 的堆栈跟踪。使用 query 参数 debug=2 可以以未恢复 panic 的相同格式导出。
- heap: 活跃对象内存分配的采样。可以为 heap 指定 gc GET 参数以在采样前运行 GC。
- mutex: 被争用的互斥锁持有者的堆栈跟踪
- profile: CPU 剖面。你可以在 seconds GET 参数中指定持续时间。获取 profile 文件后,使用 go tool pprof 命令分析剖面。
- threadcreate: 导致新 OS 线程创建的堆栈跟踪
- trace: 当前程序执行的 trace。可以在 seconds GET 参数中指定持续时间。获取 trace 文件后,使用 go tool trace 命令分析该 trace。
下载剖面
在 pprof 索引页面上点击链接会以文本格式给出剖面。这对于调试很有用,也是 Caddy 团队偏好的方式,因为我们可以扫描文本以查找明显线索,而无需额外工具。
但二进制实际上是默认格式。HTML 链接会在查询字符串中追加 ?debug= 参数以将其格式化为文本,除了(CPU)“profile”链接之外,该链接没有文本表示。
这些是你可以设置的查询字符串参数(摘自 Go 文档):
debug=N(除 cpu 以外的所有剖面): 响应格式:N = 0:二进制(默认),N > 0:明文gc=N(heap 剖面): N > 0:在剖面采样前运行一次垃圾回收seconds=N(allocs、block、goroutine、heap、mutex、threadcreate 剖面): 返回增量剖面seconds=N(cpu、trace 剖面): 对给定持续时间进行剖面
因为这些是 HTTP 端点,你也可以使用任何 HTTP 客户端,例如 curl 或 wget 来下载剖面。
剖面下载后,你可以将它们上传到 GitHub issue 评论或使用像 pprof.me 这样的站点。针对 CPU 剖面,另一个选项是 flamegraph.com。
远程访问
如果你已经可以在本地访问 admin API,可跳过本节。
默认情况下,Caddy 的 admin API 仅可通过环回接口访问。但至少有三种方法可以远程访问 Caddy 的 /debug/pprof 端点:
通过你的网站进行反向代理
一个简单的选项是直接从你的网站反向代理到它:
reverse_proxy /debug/pprof/* localhost:2019 {
header_up Host {upstream_hostport}
}
这当然会使得能连接你网站的人访问到剖面。如果这不是你想要的,你可以使用任意 HTTP 认证模块添加一些认证。
(别忘了使用 /debug/pprof/* 匹配器,否则你会代理整个 admin API!)
SSH 隧道
另一种方式是使用 SSH 隧道。这是在你的电脑与服务器之间使用 SSH 协议的加密连接。在你的电脑上运行类似下面的命令:
ssh -N username@example.com -L 8123:localhost:2019这会将 localhost:8123(在本地机器上)隧道到 example.com 上的 localhost:2019。请根据需要替换 username、example.com 以及端口。
然后在另一个终端,你可以这样运行 curl:
curl -v http://localhost:8123/debug/pprof/ -H "Host: localhost:2019"你可以通过在隧道两端都使用端口 2019 来避免需要 -H "Host: ..."(但这要求你本机上未占用 2019 端口,例如没有在本地运行 Caddy)。
当隧道处于活动状态时,你可以访问 admin API 的任意端点。对运行 ssh 的终端按 Ctrl+C 可关闭隧道。
长期运行的隧道
用上面的命令运行隧道需要你保持终端打开。如果你想在后台运行隧道,可以像这样启动:
ssh -f -N -M -S /tmp/caddy-tunnel.sock username@example.com -L 8123:localhost:2019这会在后台启动并在 /tmp/caddy-tunnel.sock 创建一个控制套接字。完成后你可以使用该控制套接字来关闭隧道:
ssh -S /tmp/caddy-tunnel.sock -O exit e远程 admin API
你也可以配置 admin API 接受授权客户端的远程连接。
(TODO:撰写关于此的文章。)
Goroutine 剖面
goroutine 转储用于了解存在哪些 goroutine 以及它们的调用栈。换句话说,它让我们了解正在执行或正在阻塞/等待的代码。
如果你点击 "goroutines" 或访问 /debug/pprof/goroutine?debug=1,你会看到 goroutine 列表及其调用栈。例如:
goroutine profile: total 88
23 @ 0x43e50e 0x436d37 0x46bda5 0x4e1327 0x4e261a 0x4e2608 0x545a65 0x5590c5 0x6b2e9b 0x50ddb8 0x6b307e 0x6b0650 0x6b6918 0x6b6921 0x4b8570 0xb11a05 0xb119d4 0xb12145 0xb1d087 0x4719c1
# 0x46bda4 internal/poll.runtime_pollWait+0x84 runtime/netpoll.go:343
# 0x4e1326 internal/poll.(*pollDesc).wait+0x26 internal/poll/fd_poll_runtime.go:84
# 0x4e2619 internal/poll.(*pollDesc).waitRead+0x279 internal/poll/fd_poll_runtime.go:89
# 0x4e2607 internal/poll.(*FD).Read+0x267 internal/poll/fd_unix.go:164
# 0x545a64 net.(*netFD).Read+0x24 net/fd_posix.go:55
# 0x5590c4 net.(*conn).Read+0x44 net/net.go:179
# 0x6b2e9a crypto/tls.(*atLeastReader).Read+0x3a crypto/tls/conn.go:805
# 0x50ddb7 bytes.(*Buffer).ReadFrom+0x97 bytes/buffer.go:211
# 0x6b307d crypto/tls.(*Conn).readFromUntil+0xdd crypto/tls/conn.go:827
# 0x6b064f crypto/tls.(*Conn).readRecordOrCCS+0x24f crypto/tls/conn.go:625
# 0x6b6917 crypto/tls.(*Conn).readRecord+0x157 crypto/tls/conn.go:587
# 0x6b6920 crypto/tls.(*Conn).Read+0x160 crypto/tls/conn.go:1369
# 0x4b856f io.ReadAtLeast+0x8f io/io.go:335
# 0xb11a04 io.ReadFull+0x64 io/io.go:354
# 0xb119d3 golang.org/x/net/http2.readFrameHeader+0x33 golang.org/x/net@v0.14.0/http2/frame.go:237
# 0xb12144 golang.org/x/net/http2.(*Framer).ReadFrame+0x84 golang.org/x/net@v0.14.0/http2/frame.go:498
# 0xb1d086 golang.org/x/net/http2.(*serverConn).readFrames+0x86 golang.org/x/net@v0.14.0/http2/server.go:818
1 @ 0x43e50e 0x44e286 0xafeeb3 0xb0af86 0x5c29fc 0x5c3225 0xb0365b 0xb03650 0x15cb6af 0x43e09b 0x4719c1
# 0xafeeb2 github.com/caddyserver/caddy/v2/cmd.cmdRun+0xcd2 github.com/caddyserver/caddy/v2@v2.7.4/cmd/commandfuncs.go:277
# 0xb0af85 github.com/caddyserver/caddy/v2/cmd.init.1.func2.WrapCommandFuncForCobra.func1+0x25 github.com/caddyserver/caddy/v2@v2.7.4/cmd/cobra.go:126
# 0x5c29fb github.com/spf13/cobra.(*Command).execute+0x87b github.com/spf13/cobra@v1.7.0/command.go:940
# 0x5c3224 github.com/spf13/cobra.(*Command).ExecuteC+0x3a4 github.com/spf13/cobra@v1.7.0/command.go:1068
# 0xb0365a github.com/spf13/cobra.(*Command).Execute+0x5a github.com/spf13/cobra@v1.7.0/command.go:992
# 0xb0364f github.com/caddyserver/caddy/v2/cmd.Main+0x4f github.com/caddyserver/caddy/v2@v2.7.4/cmd/main.go:65
# 0x15cb6ae main.main+0xe caddy/main.go:11
# 0x43e09a runtime.main+0x2ba runtime/proc.go:267
1 @ 0x43e50e 0x44e9c5 0x8ec085 0x4719c1
# 0x8ec084 github.com/caddyserver/certmagic.(*Cache).maintainAssets+0x304 github.com/caddyserver/certmagic@v0.19.2/maintain.go:67
...
第一行 goroutine profile: total 88 告诉我们这是 goroutine 剖面,以及总共有多少个 goroutine。
随后是 goroutine 列表。它们按调用栈分组,并按频率降序排列。
一行 goroutine 的语法是:<count> @ <addresses...>
该行以拥有该调用栈的 goroutine 数量开始。@ 符号表示调用指令地址(即函数指针)的开始,这些地址是 goroutine 的起源。每个指针代表一次函数调用,或调用帧。
你可能注意到许多 goroutine 共享相同的第一个调用地址。这通常是程序的 main 或入口点。有些 goroutine 不会在那里起始,因为程序有各种 init() 函数,Go 运行时也可能生成 goroutine。
随后以 # 开头的行实际上只是为读者提供的注释。它们包含 goroutine 的当前堆栈跟踪。顶部代表栈顶,即当前正在执行的代码行。底部代表栈底,或者 goroutine 最初开始运行的代码。
堆栈跟踪的格式如下:
<address> <package/func>+<offset> <filename>:<line>
地址是函数指针,然后你将看到 Go 包和函数名(如果是方法则带上类型名),以及函数内的指令偏移量。最后,可能最有用的信息是文件和行号,会出现在末尾。
完整的 goroutine 堆栈转储
如果我们将查询字符串参数改为 ?debug=2,就会得到完整转储。这包括每个 goroutine 的详细堆栈跟踪,并且相同的 goroutine 不会被合并。在繁忙服务器上此输出可能非常庞大,但信息非常有价值!
来看一个对应上述第一个调用栈的例子(已截断):
goroutine 61961905 [IO wait, 1 minutes]:
internal/poll.runtime_pollWait(0x7f9a9a059eb0, 0x72)
runtime/netpoll.go:343 +0x85
...
golang.org/x/net/http2.(*serverConn).readFrames(0xc001756f00)
golang.org/x/net@v0.14.0/http2/server.go:818 +0x87
created by golang.org/x/net/http2.(*serverConn).serve in goroutine 61961902
golang.org/x/net@v0.14.0/http2/server.go:930 +0x56a
尽管输出很冗长,但该转储唯一提供的最有用信息是每个 goroutine 的第一行和最后一行。
第一行包含 goroutine 的编号(61961905)、状态("IO wait")和存在的持续时间("1 minutes"):
- Goroutine 编号:是的,goroutine 有编号!但这些编号不会暴露给我们的代码。不过这些编号在堆栈跟踪中特别有帮助,因为我们可以看到哪个 goroutine 生成了当前的这个(见末尾:"created by ... in goroutine 61961902")。下面的工具可以帮助我们绘制可视化图表。
- 状态:这告诉我们 goroutine 当前正在做什么。你可能会看到的一些状态包括:
running:正在执行代码——太棒了!IO wait:等待网络。因为它被停在非阻塞网络轮询器上,所以不会占用 OS 线程。sleep:我们都更需要它。select:在 select 上阻塞;等待某个 case 可用。select (no cases):在空的 selectselect {}上阻塞。Caddy 在其 main 中使用一个这样的语句来保持运行,因为关闭是由其他 goroutine 发起的。chan receive:在通道接收上阻塞(<-ch)。semacquire:等待获取信号量(底层同步原语)。syscall:正在执行系统调用。会占用 OS 线程。
- 持续时间:goroutine 存在了多长时间。对发现例如 goroutine 泄漏之类的 bug 很有用。例如,如果我们期望所有网络连接在几分钟内关闭,那么当我们发现大量网络连接的 goroutine 存活数小时,这说明可能出问题。
解释 goroutine 转储
在不查看代码的情况下,我们能从上面的 goroutine 学到什么?
它大约一分钟前创建,正在等待网络套接字上的数据,并且其 goroutine 编号很大(61961905)。
从第一个转储(debug=1)我们知道它的调用栈被频繁执行,并且较大的 goroutine 编号结合短的持续时间表明存在数千万个这些相对短寿命的 goroutine。它位于名为 pollWait 的函数中,调用历史包括从使用 TLS 的加密网络连接读取 HTTP/2 帧。
因此,我们可以推断该 goroutine 正在为某个 HTTP/2 请求提供服务!它在等待来自客户端的数据。更重要的是,我们知道生成它的 goroutine 不是进程的最初几个 goroutine 之一,因为它也有较大的编号;在转储中找到那个 goroutine 会显示它是在处理现有请求期间为一个新的 HTTP/2 流而生成的。相比之下,其他具有较大编号的 goroutine 可能是由一个编号较小的 goroutine(例如 32)生成的,这表明是一个新连接刚从套接字上 Accept() 出来被处理。
每个程序都不同,但在调试 Caddy 时,这些模式通常是成立的。
内存剖面
内存(或堆)剖面跟踪堆分配,这是系统上内存的主要消耗者。分配也常常是性能问题的嫌疑对象,因为分配内存需要系统调用,这可能较慢。
堆剖面在几乎所有方面都与 goroutine 剖面类似,除了顶部行的开头不同。示例如下:
0: 0 [1: 4096] @ 0xb1fc05 0xb1fc4d 0x48d8d1 0xb1fce6 0xb184c7 0xb1bc8e 0xb41653 0xb4105c 0xb4151d 0xb23b14 0x4719c1
# 0xb1fc04 bufio.NewWriterSize+0x24 bufio/bufio.go:599
# 0xb1fc4c golang.org/x/net/http2.glob..func8+0x6c golang.org/x/net@v0.17.0/http2/http2.go:263
# 0x48d8d0 sync.(*Pool).Get+0xb0 sync/pool.go:151
# 0xb1fce5 golang.org/x/net/http2.(*bufferedWriter).Write+0x45 golang.org/x/net@v0.17.0/http2/http2.go:276
# 0xb184c6 golang.org/x/net/http2.(*Framer).endWrite+0xc6 golang.org/x/net@v0.17.0/http2/frame.go:371
# 0xb1bc8d golang.org/x/net/http2.(*Framer).WriteHeaders+0x48d golang.org/x/net@v0.17.0/http2/frame.go:1131
# 0xb41652 golang.org/x/net/http2.(*writeResHeaders).writeHeaderBlock+0xd2 golang.org/x/net@v0.17.0/http2/write.go:239
# 0xb4105b golang.org/x/net/http2.splitHeaderBlock+0xbb golang.org/x/net@v0.17.0/http2/write.go:169
# 0xb4151c golang.org/x/net/http2.(*writeResHeaders).writeFrame+0x1dc golang.org/x/net@v0.17.0/http2/write.go:234
# 0xb23b13 golang.org/x/net/http2.(*serverConn).writeFrameAsync+0x73 golang.org/x/net@v0.17.0/http2/server.go:851
第一行格式如下:
<live objects> <live memory> [<allocations>: <allocation memory>] @ <addresses...>
在上面的例子中,我们看到一次由 bufio.NewWriterSize() 做出的分配,但当前没有来自该调用栈的存活对象。
有趣的是,我们可以从该调用栈推断出 http2 包使用了一个池化的 4 KB 来向客户端写 HTTP/2 帧。如果热点路径经过优化以重用分配,你常常会在 Go 的内存剖面中看到池化对象。这可以减少新分配,堆剖面可以帮助你了解池是否被正确使用!
CPU 剖面
CPU 剖面帮助你理解 Go 程序在处理器上把调度时间主要花在哪些地方。
但是,这类剖面没有明文形式,因此在下一节我们将使用 go tool pprof 命令来帮助阅读它们。
要下载 CPU 剖面,请请求 /debug/pprof/profile?seconds=N,其中 N 是你希望收集剖面的秒数。在收集 CPU 剖面期间,程序性能可能会受到轻微影响。(其他剖面对性能几乎没有影响。)
完成后,它会下载一个二进制文件,恰如其分地命名为 profile。然后我们需要查看它。
go tool pprof
我们将以 CPU 剖面为例使用 Go 的内置剖面分析器来读取剖面,但你可以用它来分析任何类型的剖面。
运行下面的命令(如果文件名不同,请替换 "profile" 为实际文件路径),它会打开一个交互提示符:
go tool pprof profile
File: caddy_master
Type: cpu
Time: Aug 29, 2022 at 8:47pm (MDT)
Duration: 30.02s, Total samples = 70.11s (233.55%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) 这是一个你可以探索的交互工具。输入 help 会给出命令列表,o 会显示当前选项。如果你键入 help <command>,可以获得关于某个具体命令的信息。
命令很多,但一些常用命令包括:
top:显示消耗最多 CPU 的项。你可以附加一个数字,例如top 20来查看更多,或附加正则表达式来“聚焦”或忽略某些项。web:在浏览器中打开调用图。这是可视化查看 CPU 使用情况的好方法。svg:生成调用图的 SVG 图像。它与web相同,但不会打开浏览器,SVG 会保存在本地。tree:调用栈的表格视图。
我们先从 top 开始。你会看到如下输出:
(pprof) top
Showing nodes accounting for 38.36s, 54.71% of 70.11s total
Dropped 785 nodes (cum <= 0.35s)
Showing top 10 nodes out of 196
flat flat% sum% cum cum%
10.97s 15.65% 15.65% 10.97s 15.65% runtime/internal/syscall.Syscall6
6.59s 9.40% 25.05% 36.65s 52.27% runtime.gcDrain
5.03s 7.17% 32.22% 5.34s 7.62% runtime.(*lfstack).pop (inline)
3.69s 5.26% 37.48% 11.02s 15.72% runtime.scanobject
2.42s 3.45% 40.94% 2.42s 3.45% runtime.(*lfstack).push
2.26s 3.22% 44.16% 2.30s 3.28% runtime.pageIndexOf (inline)
2.11s 3.01% 47.17% 2.56s 3.65% runtime.findObject
2.03s 2.90% 50.06% 2.03s 2.90% runtime.markBits.isMarked (inline)
1.69s 2.41% 52.47% 1.69s 2.41% runtime.memclrNoHeapPointers
1.57s 2.24% 54.71% 1.57s 2.24% runtime.epollwait
前十名的 CPU 消耗全部集中在 Go 运行时——特别是大量的垃圾回收(记住 syscalls 被用于释放和分配内存)。这提示我们可以通过减少分配来改善性能,值得查看堆剖面。
好,但如果我们想查看自己代码的 CPU 使用情况呢?我们可以忽略包含 "runtime" 的模式,比如这样:
(pprof) top -runtime
Active filters:
ignore=runtime
Showing nodes accounting for 0.92s, 1.31% of 70.11s total
Dropped 160 nodes (cum <= 0.35s)
Showing top 10 nodes out of 243
flat flat% sum% cum cum%
0.17s 0.24% 0.24% 0.28s 0.4% sync.(*Pool).getSlow
0.11s 0.16% 0.4% 0.11s 0.16% github.com/prometheus/client_golang/prometheus.(*histogram).observe (inline)
0.10s 0.14% 0.54% 0.23s 0.33% github.com/prometheus/client_golang/prometheus.(*MetricVec).hashLabels
0.10s 0.14% 0.68% 0.12s 0.17% net/textproto.CanonicalMIMEHeaderKey
0.10s 0.14% 0.83% 0.10s 0.14% sync.(*poolChain).popTail
0.08s 0.11% 0.94% 0.26s 0.37% github.com/prometheus/client_golang/prometheus.(*histogram).Observe
0.07s 0.1% 1.04% 0.07s 0.1% internal/poll.(*fdMutex).rwlock
0.07s 0.1% 1.14% 0.10s 0.14% path/filepath.Clean
0.06s 0.086% 1.23% 0.06s 0.086% context.value
0.06s 0.086% 1.31% 0.06s 0.086% go.uber.org/zap/buffer.(*Buffer).AppendByte
很明显,Prometheus 指标是另一个主要的消耗源,但你会注意到它们的累积时间远小于上面显示的 GC。明显的差异表明我们应该优先减少 GC。
我们用 q 退出该剖面,然后对堆剖面运行相同命令:
(pprof) top
Showing nodes accounting for 22259.07kB, 81.30% of 27380.04kB total
Showing top 10 nodes out of 102
flat flat% sum% cum cum%
12300kB 44.92% 44.92% 12300kB 44.92% runtime.allocm
2570.01kB 9.39% 54.31% 2570.01kB 9.39% bufio.NewReaderSize
2048.81kB 7.48% 61.79% 2048.81kB 7.48% runtime.malg
1542.01kB 5.63% 67.42% 1542.01kB 5.63% bufio.NewWriterSize
...
正中要害。近一半的内存分配严格用于我们使用 bufio 包时的读写缓冲。因此,我们可以推断出优化代码以减少缓冲会很有收益。(对 Caddy 的相关补丁就实现了这一点)
可视化
如果我们改用 svg 或 web 命令,就会得到剖面的可视化:
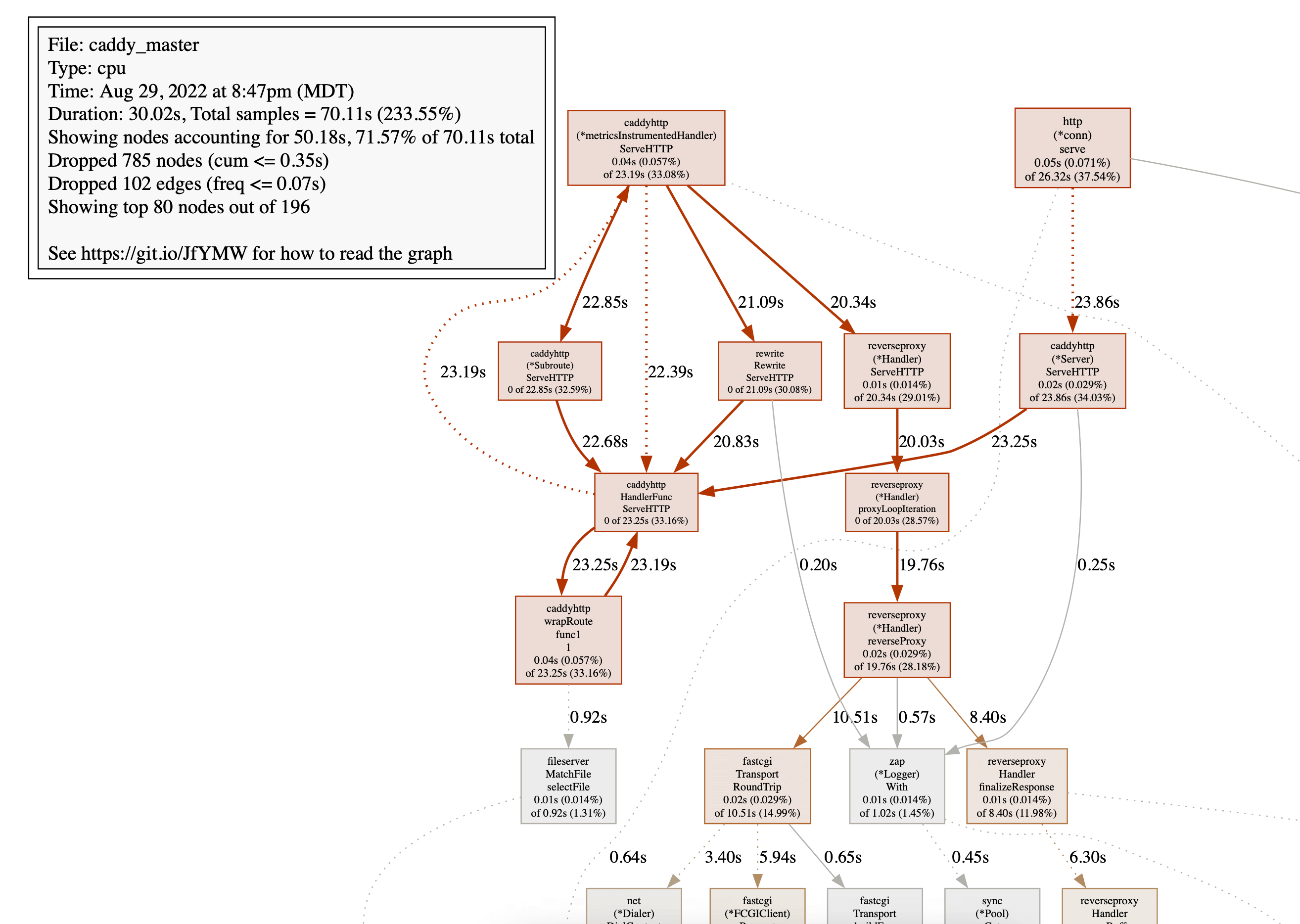
这是一个 CPU 剖面,但其他类型的剖面也可得到类似的图。
想了解如何阅读这些图,请参阅 pprof 文档。
对比剖面(Diff)
在你做出代码更改后,可以使用差异分析(“diff”)来比较前后效果。下面是一个堆剖面的 diff:
go tool pprof -diff_base=before.prof after.prof
File: caddy
Type: inuse_space
Time: Aug 29, 2022 at 1:21am (MDT)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for -26.97MB, 49.32% of 54.68MB total
Dropped 10 nodes (cum <= 0.27MB)
Showing top 10 nodes out of 137
flat flat% sum% cum cum%
-27.04MB 49.45% 49.45% -27.04MB 49.45% bufio.NewWriterSize
-2MB 3.66% 53.11% -2MB 3.66% runtime.allocm
1.06MB 1.93% 51.18% 1.06MB 1.93% github.com/yuin/goldmark/util.init
1.03MB 1.89% 49.29% 1.03MB 1.89% github.com/caddyserver/caddy/v2/modules/caddyhttp/reverseproxy.glob..func2
1MB 1.84% 47.46% 1MB 1.84% bufio.NewReaderSize
-1MB 1.83% 49.29% -1MB 1.83% runtime.malg
1MB 1.83% 47.46% 1MB 1.83% github.com/caddyserver/caddy/v2/modules/caddyhttp/reverseproxy.cloneRequest
-1MB 1.83% 49.29% -1MB 1.83% net/http.(*Server).newConn
-0.55MB 1.00% 50.29% -0.55MB 1.00% html.populateMaps
0.53MB 0.97% 49.32% 0.53MB 0.97% github.com/alecthomas/chroma.TypeRemappingLexer如你所见,我们将内存分配减少了大约一半!
差异也可以可视化:
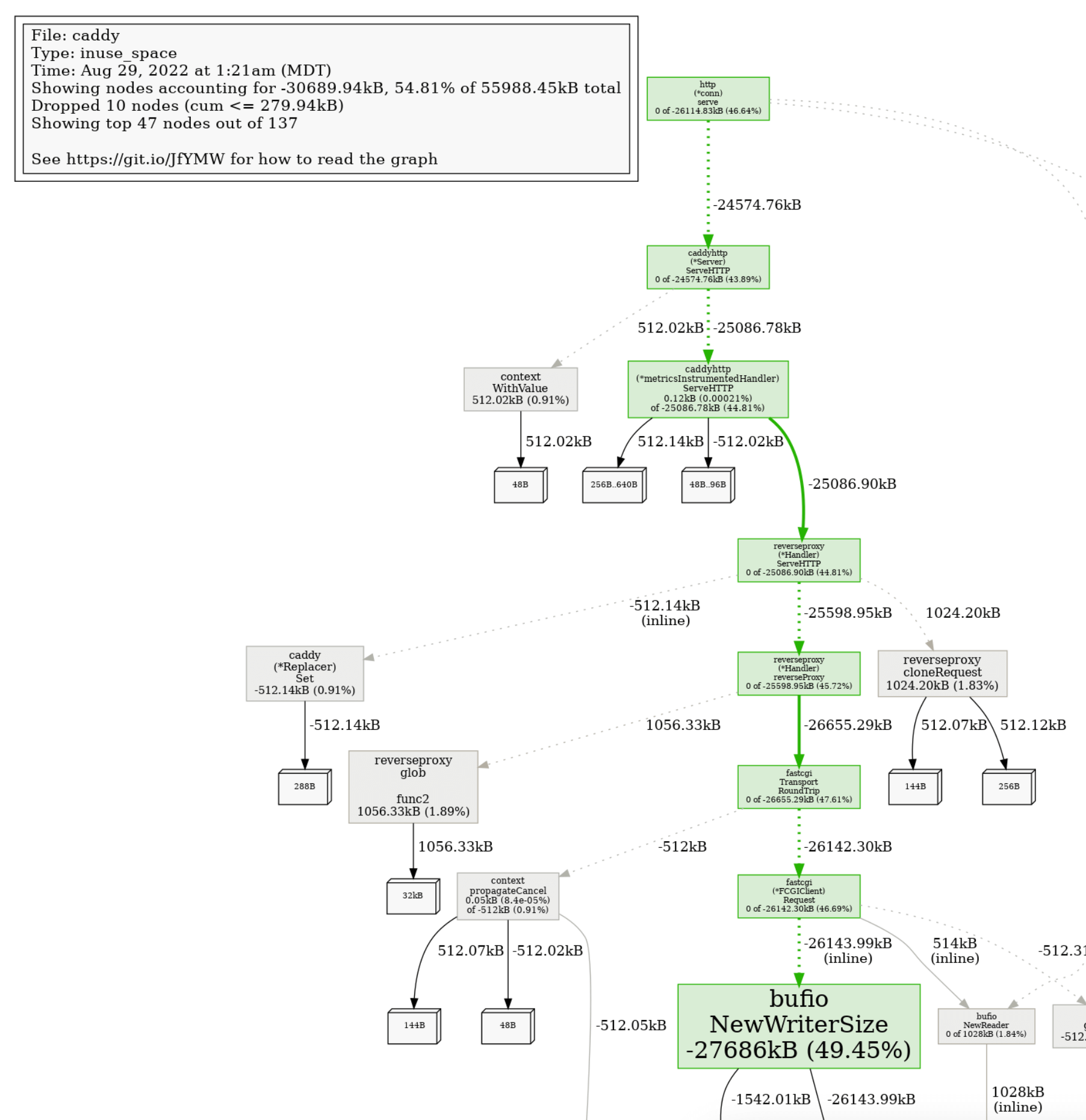
这让更改如何影响程序各部分的性能一目了然。
延伸阅读
程序剖面有很多需要学习的内容,我们这里只涉及了皮毛。
要真正把“剖析”做到专业水平,考虑阅读以下资源: